I noticed MEGAN was misreading some genbank names, annotating them as ‘root’ instead of the species name (Girella sp.). The funny thing is it seems to work for some IDs that contain similar key words but there’s obviously something in a couple of these names that is causing it to be thrown off. Perhaps it’s the term ‘mitochondrial’? We didn’t have this error with this same sequence on a previous version of MEGAN.
Hi Daniel,
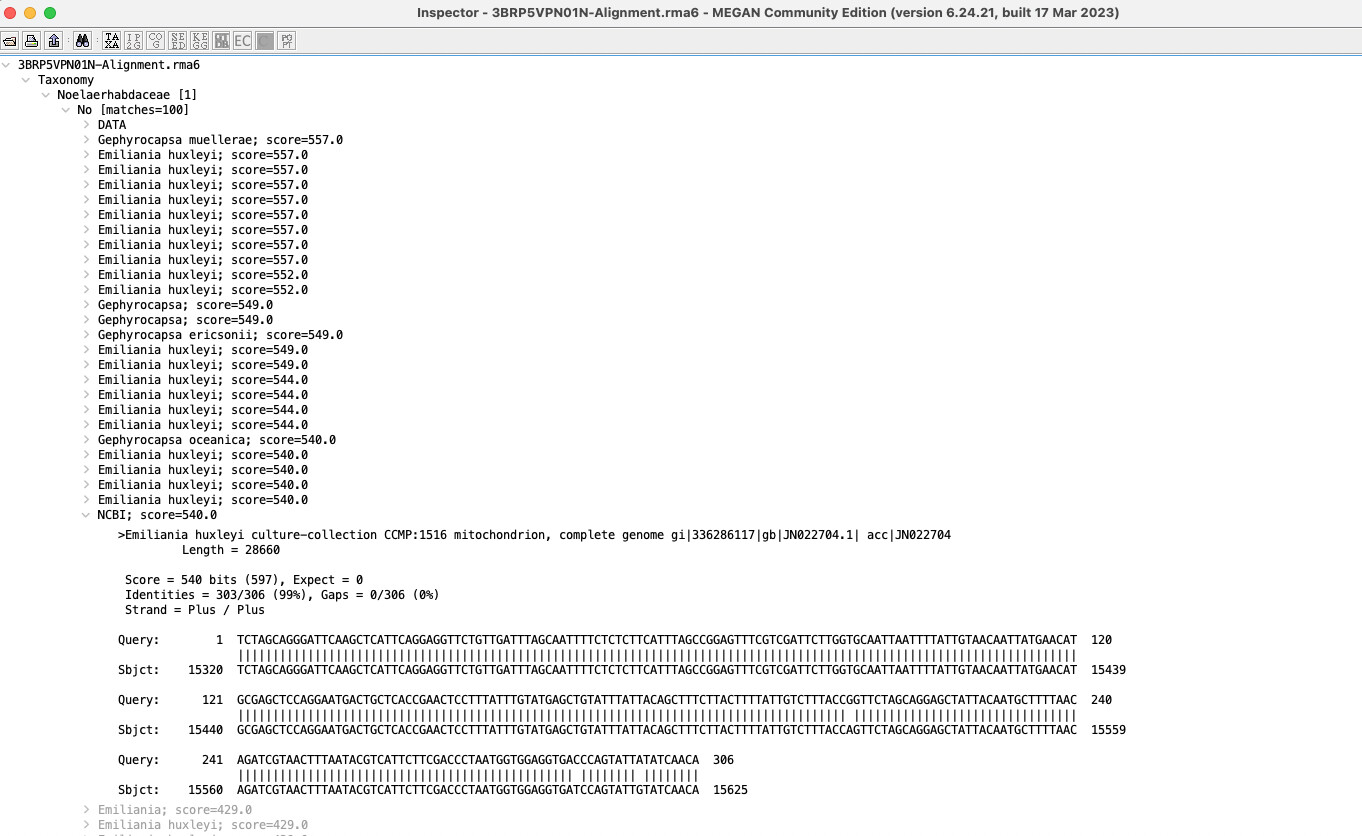
Apologies for not getting back to you earlier about this problem! It’s resurfaced in another example, where a genbank sequence is being assigned the taxonomy of “NCBI” (that character string) within MEGAN6. I’ve updated to the most recent version and still see this behavior. To test I ran an online blastn search on a sequence, imported it, and here am attaching a screenshot of the behavior within MEGAN6. I’ve also attached the XML file. I imported the blast results within the GUI application, with Parse Taxon Names enabled (all options remained just the standard the are initially selected by the program after downloading). Thanks in advance for any help! 3BRP5VPN01N-Alignment.xml (184.6 KB)
(
Thank you for pointing out the problem. As long as the issues doesn’t occur too often, it won’t confuse the LCA algorithm.
I just took a look at your example file, I get an assignment for that reference that makes sense: Emiliania huxleyi.
The code that parses taxon names contains a number of different heuristics to try and make the best assignment possible and also tries to find multiple taxon assignments in a header line (makes more sense when using a non-redundant database where sequences represent more than one taxon) and my guess is that it identified both a prokaryote and some non-cellular entity and thus placed the reference onto the root node…
Thank you for the quick response! It isn’t a problem here for this particular sequence since there are so many other E. huxleyi good blast hits, but we have other sequences where a ‘NCBI’ hit is one of only 2-4 blast hits overall, so because we have our LCA parameter set to 0.85, it assigns those sequences to that root “NCBI” node. I was wondering if it is possible to get around this issue by ignoring blast hits to this fake ‘NCBI’ ID. When using the blast2rma tool, is there a way to feed in taxon names to ignore? Thanks so much for the help!
Also just an idea to check, do you think MEGAN6 interprets the term ‘mitochondrion’ as a prokaryotic organism? Nothing else in the sequence description looks like it would cause that labeling problem.
No, that is not a word that appears in the file that MEGAN uses (ncbi.map). I’ve tried to figure out what caused the problem, but I’m not having any luck because I haven’t been able to reproduce it. I can see that Emiliania huxleyi appears as a Eukaryote and there are some viruses that have Emiliania huxleyi in their name…
I also saw that the accession mentioned maps to taxon id 2903, which is Emiliania huxleyi:
sqlite3 megan-nucl-Feb2022.db
sqlite> select Taxonomy from mappings where Accession=‘JN022704’;
2903
Hi Daniel, I have another megan results file from my environmental data that includes 30 examples of ASVs that were assigned to ‘NCBI’ but the .rma6 file is too large to attach here. Is there any information I can export and share that would help? How can I find the ncbi.map file associated with a genbank sequence to investigate these examples? Thanks!