Hi,
I’ve been trying to get the number of assigned taxonomy reads for all my samples but im not sure if im looking at the right place. According to the image below it indicates that 31,964,632 reads has been assigned. Does the number indicates the number of assigned taxonomy reads, excluding unclassified sequences & other sequences?
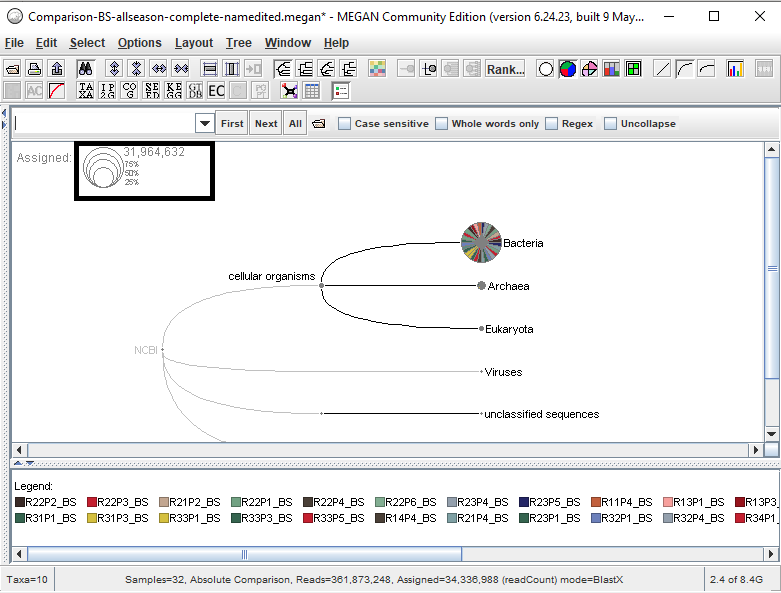
When i group the same samples, i get 31,949, 708
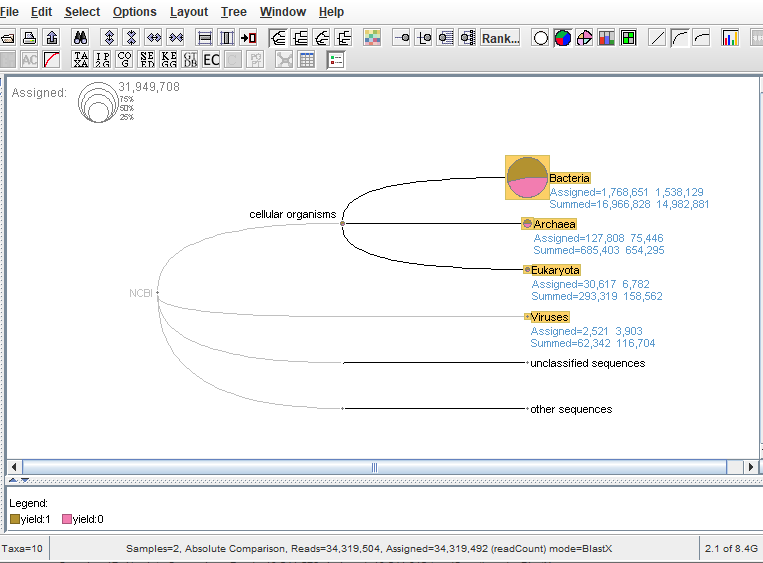
Also, when i display all the reads without grouping the samples it is indicated that i have a total reads of 361,873,248 (as shown at the bottom panel of the first image) but when i group the same amount of samples into 2 different groups and ‘compare absolute’, the total number of reads were indicated as 34,319,504. Why such a difference? This is pretty confusing to me. Any help will be appreciated.
Thank you